
Unique identifiers
Overview
Ortto’s Unique identifiers enable users to manage the recognition of each individual person and accounts (previously organizations) record within their Ortto account’s customer data platform (CDP), including those integrated from data sources. These identifiers help Ortto distinguish between unique records and duplicates when importing people (contacts) and accounts (previously organizations).
Accessing unique identifiers
To access the unique identifier page, go to Settings > Customer data > Unique identifiers
Managing unique identifiers
The unique identifiers page allows users to:
How do unique identifiers work?
Ortto initially designates Email as the primary identifier for contacts, with no fallback identifier.
During the import of contacts, Ortto cross-references incoming records with those already present in your CDP. For instance, using the default criteria:
- Does the incoming person's Email match an existing record?
If no match is detected, the incoming contact is appended as a new record to your CDP. However, if a match is found, it will be merged based on the merge strategy you have chosen for that incoming data source.
Set unique identifiers
- Navigate to the Unique identifiers page.
- Choose up to two unique identifiers for each people and accounts (previously organizations) record, including an optional secondary identifier for both the primary and fallback identifiers. Options for identifiers include Ortto’s system fields, fields from integrated data sources, or custom fields.
- Eligible fields for unique identifiers must be text-type (string) or a phone number.
- Learn more about supported Field types.
- Use the Trash icon to remove the optional second identifier if needed.
TIP: Consider the following when selecting your unique identifiers:
- Evaluate how your chosen identifiers may impact imported records and your merge strategy. For example, if two records have different emails but match by phone number, setting the primary identifier to email without a fallback for phone number could result in both records being created.
- Reflect on how your chosen identifiers might affect matches for existing records. Could a chosen identifier be missing for some records, potentially leading to duplicates?
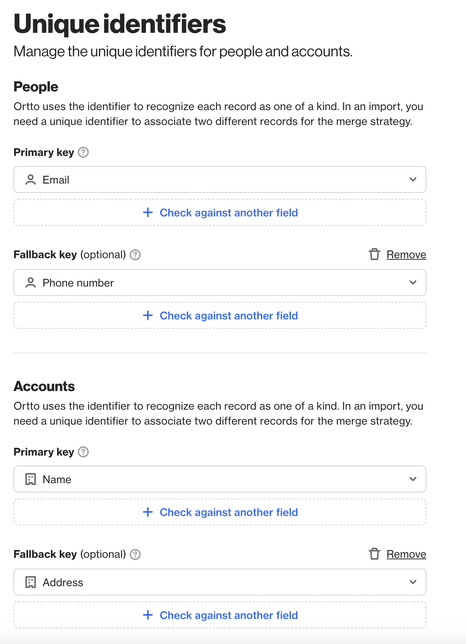
Set a secondary field for an identifier
Users can set a secondary identifier field which will mean that contacts can be matched against a second field, in addition to the primary key. You can add a secondary field for the primary or fallback key, for both the contact and account identifiers. This might be things such as:
A secondary email:
- Contacts may have multiple email addresses recorded for various interactions such as work and personal. In this scenario, users could have the primary Email field and an additional Secondary email field. The Email would be set as the primary key. Then, under Check against another field, users would select Secondary email.
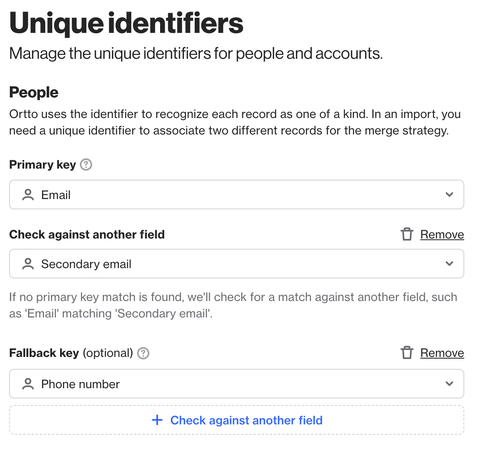
Screenshot showing secondary email as the secondary field.
EX: If a contact has a primary email (e.g. lucy@locksmithlucy.com) and a secondary email (e.g. lucy.s@gmail.com), both would be checked during CSV imports, API requests, and data syncs (e.g. from Salesforce / Pipedrive). Records using either email will be correctly matched and updated.
NOTE: If using a secondary email, when sending a campaign this setting does not impact which email is sent to.
Learn more about how to configure email sends to a secondary address.
Phone number:
EX: A contact signs up via your website using their email address, but later completes a purchase in-store and provides their mobile number. When that phone number is imported from your system, Ortto checks it against the Phone number field of your existing contacts and merges the record correctly, keeping all activity in a single profile.
An external ID:
EX: Your e-commerce platform assigns every customer a unique ID (e.g., cust_8472). When syncing data to Ortto via the API, you pass this as the External ID. If a contact later updates their email address, Ortto can still match incoming records to the correct profile using this consistent identifier.
NOTE: When using Check against another field, Ortto will match the incoming primary and secondary fields against your existing contacts
If using the Fallback key, Ortto will first match the incoming primary key against your existing contacts. If the primary key is not available, we will then match the incoming secondary field against your contacts.